Discussion¶
Data preprocessing¶
For input data, I just built a corpus by using raw, copy-pasted text that sometimes included numbers and other symbols. A preprocessing was definitely necessary. I first stripped out all non-letter characters (keeping language-specific letters such as German umlauts). Then, I split the text up in words and reduced the corpus to keep only unique words, i.e. one copy of each word. I figured this step was reasonable since I did not want the model to learn the most common words, but instead to get an understanding of the entire corpus’ structure.
After this, most text corpora ended up as a list of 1000 to 2000 words.
The RNN architecture¶
The question which type of neural network to use was easily answered. Recurrent neural networks can model language particularly well, and were the appropriate type for this task of word generation.
However, to my knowledge, finding the ‘perfect’ RNN architecture is still somewhat of a black art. Questions like how many layers, how many units, and how many epochs have no definite answer, but rely on experience, intuition, and sometimes just brute force.
I wanted a model that was as complex as necessary, but as simple as possible. This would save training time. After some experiments, I settled for a two-layer LSTM 50 units each, training it for 500 epochs and a batch size of 64 words. The words this model outputs sound good enough that I didn’t put any more energy in fine-tuning the architecture.
Sampling Temperature¶
The RNN generates a new name character by character. In particular, at any given step, it does not just output a character, but the distribution for the next character. This allows us to pick the letter with the highest probability, or sample from the provided distribution.
A nice touch I found is to vary the temperature of the sampling procedure. The temperature is a parameter that adapts the weights to sample from. The “standard” temperature 1 does not change the weights. For a low temperature, trending towards zero, the sampling becomes less random and the letter corresponding to the maximum weight is chosen almost always. The other extreme, a large temperature trending towards infinity, will adjust the weights to a uniform distribution, representing total randomness. You can lower the temperature to get more conservative samples, or raise it to generate more random words. For actual text sampling, a temperature below 1 might be appropriate, but since I wanted new words, a higher temperature seemed better.
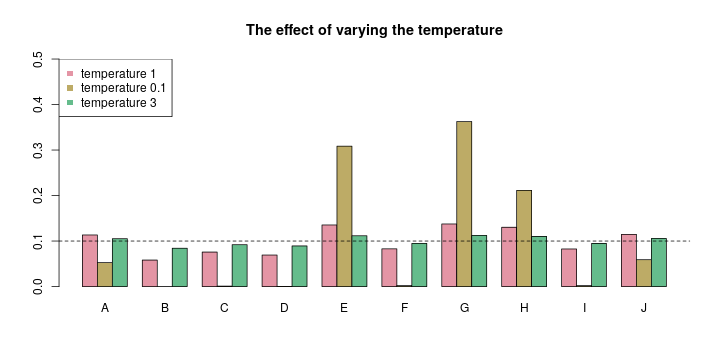
In the image above, imagine we want to sample one letter from A, B, …, J. Your RNN might output the weights represented by the red bars. You’d slightly favor A, E, G, H, and J there. Now if you transform these weights with a very cold temperature (see the yellow-ish bars), your model gets more conservative, sticking to the argmax letter(s). In this case, you’d most likely get one letter of E, G, and H. If you lower the temperature even further, your sampling will always return the argmax letter, in this case, a G.
Alternatively, you can raise the temperature. In the image above, I plotted green bars, representing a transformation applied with a temperature of 3. You can still see the same preferences for E, G, and H, but the magnitude of the differences is much lower now, resulting in a more random sampling, and consecutively, in more random names. The extreme choice of a temperature approaching infinity would result in a totally random sampling, which then would make all your RNN training useless, of course. There is a sweet spot for the temperature somewhere, which you have to discover by trial-and-error.